Make the right mobile architecture decisions


In business as in life, some choices have consequences that are more easily reversed than others. It helps to know the difference.
As we speak, many mobile marketers are accidentally making big choices, as it relates to data strategy and architecture, that will have lasting implications on the long-term health of their businesses without fully realizing it.
It’s one thing to take a calculated risk and live with the consequences when it doesn’t go your way. It’s anothe to not know the immutability of your actions until it’s too late. It’s as if you got your arm painted one day with henna only to realize, many weeks later, it was actually a permanent tattoo.
Whoops.
And that’s exactly what’s happening. It’s somewhat understandable given that the mobile marketing discipline is, in a sense, still in its adolescence. Further complicating matters is the speed at which mobile businesses need move and the fact that growth—particularly, rapid growth—can hide a lot of bad habits. Still, the outcomes are regrettable, to say the least.
Want to avoid it happening to you? Read on.
The accidental data strategist
There is an abundance of tool choices available for mobile marketing and analytics. Since most people find that no single one can handle all of their business needs, most marketers end up selecting multiple tool providers, each at various points in time.
App is crashing? Implement a crash reporting SDK. Want to understand user flows and cohorts? Implement an analytics SDK (or more likely two). Want to send push notifications? Implement a marketing automation SDK. Need to re-engage users? Implement a retargeting SDK.
Having multiple tools is not the problem. The problem is how these tools get implemented when taking an incremental approach that doesn’t account for long-term consequences. Typically, it looks something like this (only a lot messier when you consider the average app has at least a half dozen marketing-related SDKs):
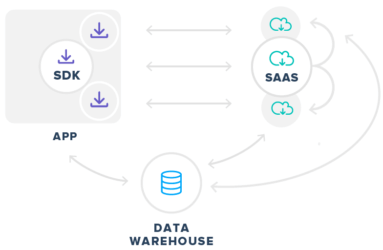
The architecture has several potential downsides, some of which only become evident over time. You may find yourself with multiple SDKs sending and receiving very similar sets of data, creating unnecessary but significant overhead within the app as well as privacy and security risks. Users can experience app crashing and latency issues, which lead to permanent uninstalls. Engineering roadmaps could need to be diverted to untangling and fixing messy code. Progress on marketing initiatives can be stuck until the SDK traffic jams get resolved. Of course, as luck would have it, all of these typically manifest during our busiest season, or just as competitors are putting on the gas.
“If only I knew then what I know now…” is a common refrain from marketers, engineers and product managers who find themselves in this place, having arrived there all too often by accident rather than by design.
The intentional data strategist
In contrast, companies that are highly intentional about their data strategies, and the resulting architectures associated with them, can create significant competitive advantages that endure over long periods of time.
Typically, the strategies associated with an intentional approach get implemented in one of two ways.
One end state is that the company will not send any data to partners directly from within their app, under any circumstances. Under this scenario, app data is sent only to an internal data warehouse, and from there a series of server-to-server integrations are built by their in-house engineering teams to enable third-party services:
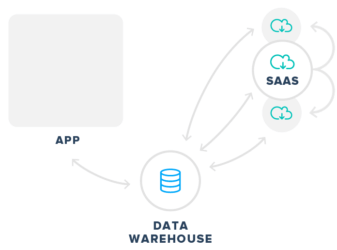
In reality, this approach is employed by only the very biggest mobile apps, such as Facebook and Twitter. The reason is that the amount of engineering resources required to configure and maintain a “Walled Garden” is significant. In addition, unless there are robust APIs, the setup can limit the speed at which data is sent to partners, inhibiting growth. For these reasons, the approach most companies (who aren’t Facebook) end up turning toward is the second, which looks more like this:
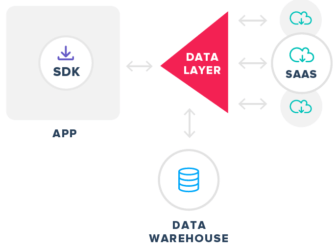
Under this scenario, you still maintain a best-in-breed stack, but it’s built and orchestrated around a central data layer. The data layer allows you to collect customer data once and then connects it to all of your various partners through server-to-server integrations in a controlled fashion.
The data hub model eliminates the overhead associated with client-side (SDK) integrations and enables marketers to get economies of scale from a single engineering initiative (integrated once, send anywhere). The data layer also serves as a single source of truth for data across the enterprise.
Whatever approach you end up taking, make it an intentional one. There is nothing wrong with a decentralized data strategy per se, but you have to know what you’re getting into.


Latest from mParticle




Try out mParticle
See how leading multi-channel consumer brands solve E2E customer data challenges with a real-time customer data platform.
Startups can now receive up to one year of complimentary access to mParticle. Receive access