From spreadsheet to source code: Leveraging mParticle’s Data Plan Builder
Effective data planning is critical to ensuring that the data entering an organization's internal systems is accurate, reliable, and actionable. mParticle’s Data Plan Builder is available to help both mParticle customers and prospects with the key aspects of data planning: collaboration, implementation, and continuous iteration.


What is data planning?
Data planning is a process in which data stakeholders throughout an organization decide what data to collect and establish rules for the structure and naming conventions of that data. These rules are recorded in a centralized document called a data plan, which then serves as a source of truth regarding data for the entire organization.
Done effectively, data planning helps companies ensure the quality of their data, and facilitate more seamless access to data across the entire organization. But this can be a significant hurdle, however, even for organizations with a mature data practice.


Why is data planning hard?
Multiple teams rely on data to make decisions and meet goals. Effective data planning requires collaboration between these teams to ensure that the resulting plan reflects their unique use cases. Ideally, data planning should be an ongoing and iterative effort carried out by a cross-functional team that includes input from:
- Data end users (including marketers, product managers, and data scientists)
- Data privacy- and governance-focused teams
- Technical teams that will implement the data plan as code
Aligning multiple stakeholders throughout the organization to collaborate on data planning can be challenging, however. This is especially true within enterprise organizations in which large teams tend to function independently, and each team’s workflows do not necessarily overlap with those of other data stakeholders. The more independently teams function, the harder it is to develop a smooth process in which multiple teams can contribute to data planning.
Additionally, for non-technical data users like marketers and product managers, it can often be challenging to translate their business goals into the data points requirements that developers will use to implement them as code. When end users do not deliver their data requirements to the implementation team with clearly defined events, attributes, and naming conventions, developers are left to fill in the gaps. This introduces a high probability of errors and inconsistencies in implementation, and makes data implementation a more time-consuming task for developers.
A common tool to align all teams: The spreadsheet
At mParticle, we partner with myriad consumer-facing brands across a variety of industries to help them overcome challenges related to their customer data. In this process, we learned that in order for different teams to collaborate smoothly and effectively on data planning, they need a simple, universal tool in which to work. Our solution? The humble spreadsheet.
Spreadsheets are the lowest common denominator for every data stakeholder, and a lingua franca for all teams across an organization. They are easy to understand, create, and update, and provide an ideal format for preserving structural hierarchies and enforcing naming consistency within data, both of which give non-technical users a smooth onramp for translating data requirements into technical specifications.
Even if your team is not currently working with mParticle, our Data Plan Builder can still serve as your centralized environment to collaborate on data planning, and translate these plans into a format your engineers can easily use to implement data collection throughout your sites and apps.
Let’s get started!
Using the Data Plan Builder
We knew this solution had to reduce friction rather than create it, which is why the Data Plan Builder leverages one of the most commonly used platforms in business today: Google Sheets. The builder provides six industry-specific templates for Travel, QSR, Gaming, FinTech, Retail, and Media as well as a generic starter template to help teams easily define plans and generate schema that align with their unique use cases.
Each template provides detailed instructions on how to define your events and attributes. To start, simply clone whichever template you’d like to use by selecting File > Make a copy. Once your template copy is ready, you can begin creating the Users, Events, and Attributes tabs to define your data plan.
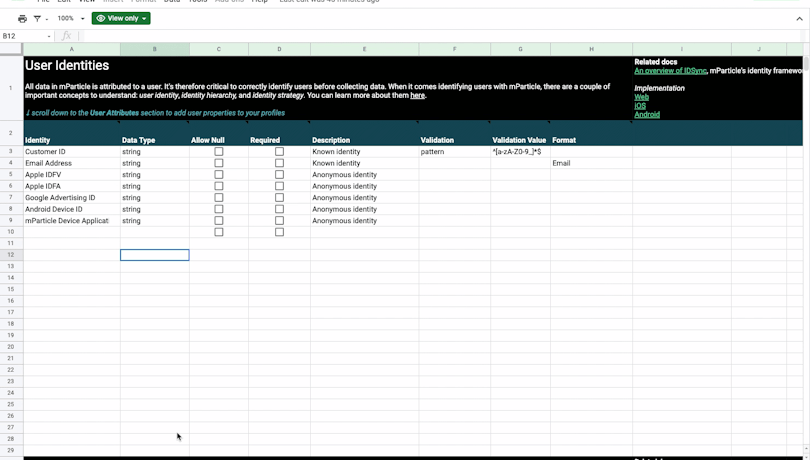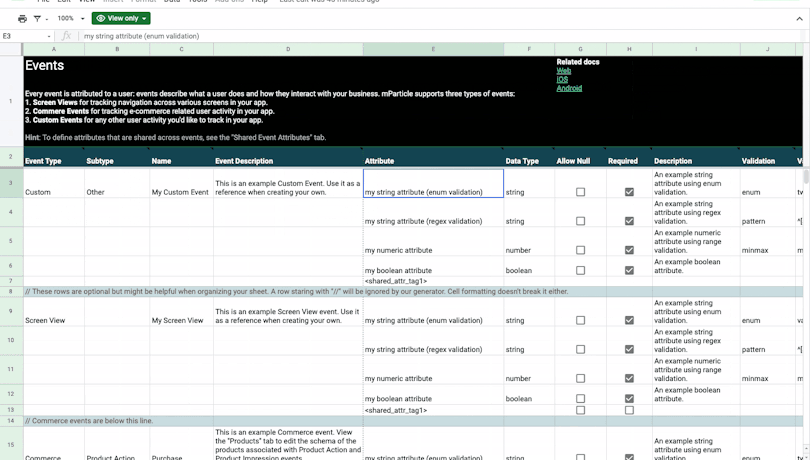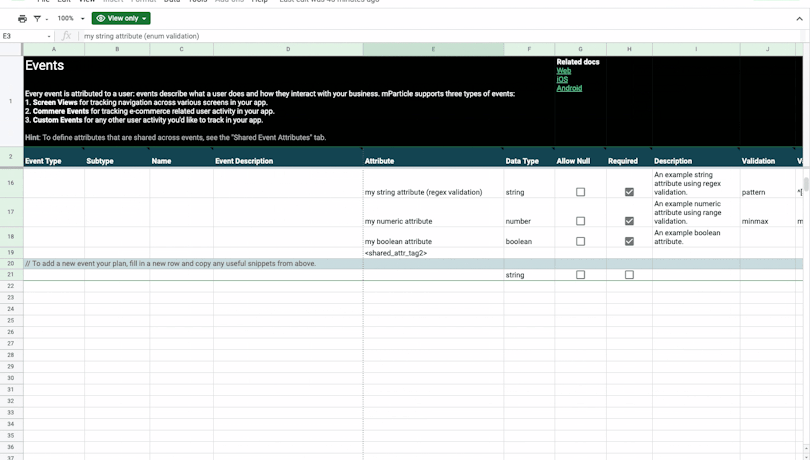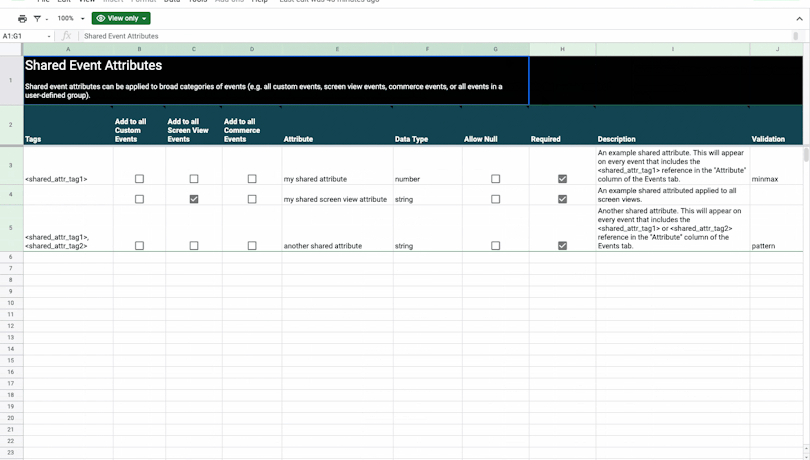
Defining user identities and attributes
All data in mParticle is attributed to a user, and the Users tab in the data plan builder is where you can define your user identities (which will be governed by your identity hierarchy) and user attributes (user-specific data that will be attached to each user profile built in mParticle). To learn more about the concepts of User Identity, Identity Hierarchy, and Identity Strategy, visit this tab of the Data Plan Builder.
Defining events
The Events tab is where you can define your user events, which are used to capture user interactions across your digital touchpoints. The three types of events that mParticle supports are:
- Screen Views (for tracking navigation across screens in your applications)
- Commerce Events (for tracking eCommerce related user activity)
- Custom Events (to track all other user behaviors and interactions that matter)
Defining shared event attributes
In the Events tab, you will notice that column “E” is labeled “Attribute,” and each predefined event has several attributes associated with it. Attributes are the individual data points that add detail to an event. For example, consider the event below:
View Video
Source Page: ‘Recently Watched’
Season: ‘2’
Episode: ‘5’
Here, “View Video” is the name of the event, and “Source Page,” “Season,” and “Episode” are all attributes that give us context about this action. Whenever possible, it is best practice to adhere to the DRY (Don’t Repeat Yourself) principle and reuse attributes across multiple events, and the Shared Event Attributes tab is where you can create these attributes that will be repurposed throughout your data plan, as well as validations you’d like to place on them.
Translating your data plan into a JSON schema
Once you have defined your data plan, the Data Plan Builder provides you with a seamless one-click process for translating the users, events, and attributes you have defined into a JSON schema that engineers can use to implement the data plan without filling in any gaps or resorting to guesswork.
Simply select mParticle > Generate Data Plan from the Google Sheet menu:


Once the script runs, you can navigate to the Output tab in the Data Plan Builder where you will see your data plan represented as a JSON schema. From here, if you’re an mParticle customer, you can copy/paste the JSON into the mParticle UI (shown above).
Having the plan represented as JSON also allows developers to seamlessly translate the schema into data collection code for Web, iOS and Android in a variety of ways. Here are two approaches to handling data plan implementation:
Using the Snippet tool
The Snippet tool is an excellent option for quickly generating data collection code across platforms, and you don’t need to be leveraging mParticle to leverage this product. Using the Snippet tool, select your platform of choice, paste your data plan into the Snippet tool’s UI, and the tool will automatically generate code that you can implement through your apps and websites to accurately collect the data that your plan specifies.
Using the Data Planning API
Alternatively, if you are currently working with mParticle, the Data Planning API allows you to fetch data plans from your mParticle workspace and include them in any development environment. This video demo walks through that process.
Start leveraging data quality features
While using the Data Plan Builder alone can help teams build a data plan, leveraging it alongside mParticle delivers several additional data quality benefits. For example, the mParticle Live Stream highlights incoming data that does not match the expectations laid out in the data plan, allowing you to quickly prevent unplanned data from entering your downstream channels. Watch a demo showing how Live Stream lets you identify data errors as they occur, and quickly debug the event collection code that produced this error based on real time feedback.








