What is a UUID?
The challenge of identifying data shared between systems dates back to the advent of networked computing. One of the earliest solutions to this problem, the Universally Unique Identifier (UUID), is still in wide use today. Here, we’ll explore this ever-present data identifier in detail.


Prior to the 1980s, computers were largely antisocial creatures. They lived in isolation, not speaking or interacting with each other at all. The information they housed never left the confines of the hardware that stored it, and to “share” data was to physically bring a computer to another location. Although pre-networked computers were wondrous machines for their time, their muteness imposed a severe limitation on their utility.
A company called Apollo Computer, founded in 1980, set out to change this. One of the earliest innovators in this space, Apollo laid the foundation for an era of rapid growth in computer networking by creating the Networked Computing System (NCS), a set of tools and protocols that helped software developers build “distributed” applications through which computers on the same network could share data. One standard the NCS laid out was a system for labeling information in order for it to be recognized when shared between machines, and thus the concept of the UUID was born.
What is a UUID?
A Universally Unique Identifier (UUID) is a 36-character alphanumeric label used to provide a unique identity to any collection of information within a computing system. Owing to their extremely low probability of duplication, UUIDs are a widely adopted tool for giving persistent and unique identities to practically every type of data imaginable.
The specifications and format of UUIDs have evolved since this earliest iteration in the NCS, but the core features remains the same: UUIDs are easy to generate, truly unique, and simple for applications to support and parse. For these reasons, they are widely adopted across applications from social networks to data warehouses.
UUID versions
Today there are five different UUID versions. Each version has slightly different strengths, and therefore may be suited for different use cases. Here is a breakdown of the main differences, and characteristics of the different UUID versions:
Version 1 and 2
Version 1 UUIDs are sometimes referred to as being “time-based” since they incorporate the datetime at which they were generated. In addition to the datetime, the final section of these UUIDs is derived from the media access controller (MAC) address of the generating device. They consist of five separate sections separated by hyphens:

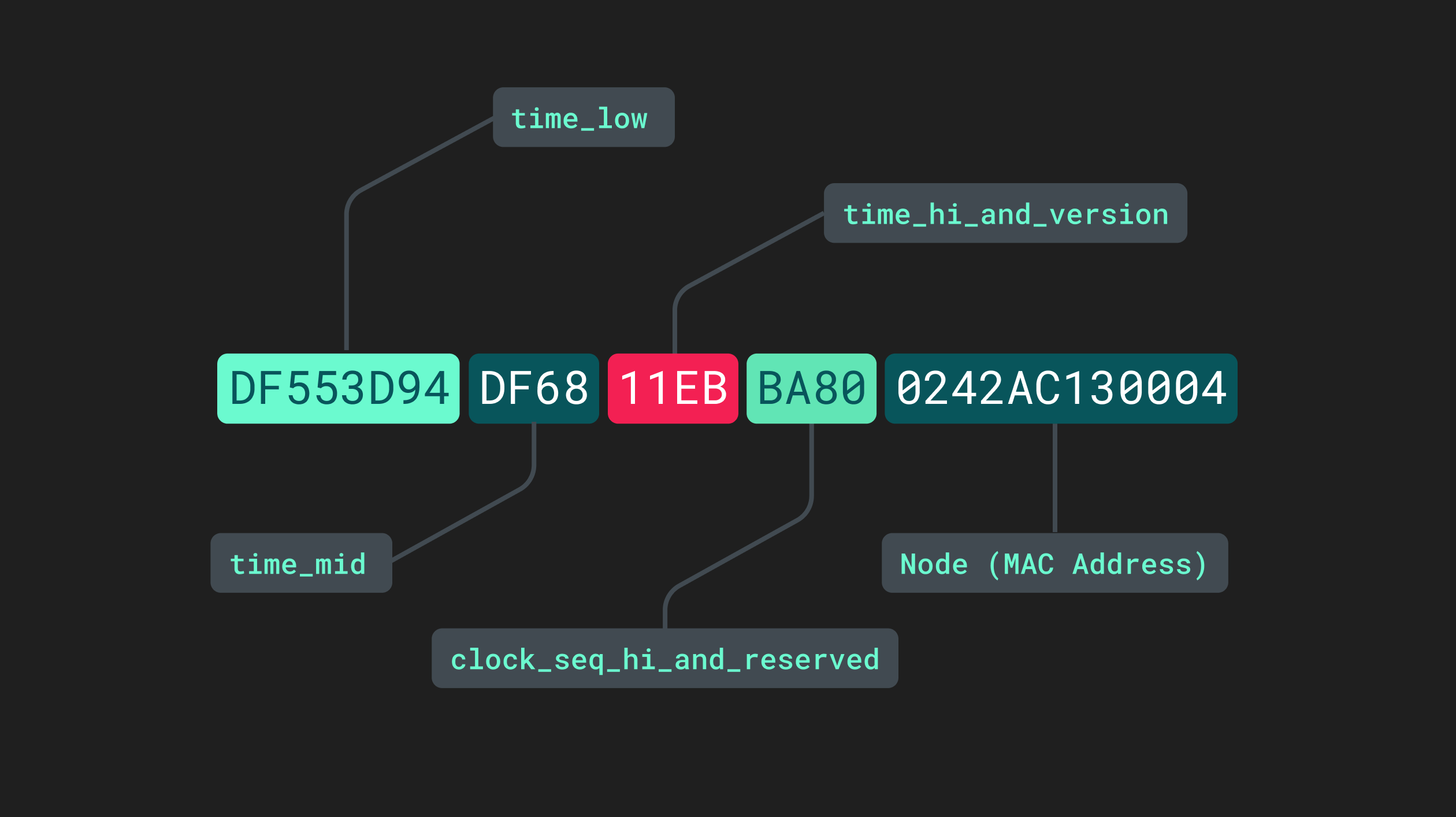
Different sections of a version 1 UUID.
The time_low, time_mid, and time_high_and_version sections pertain to the low, medium, and high timestamps within the current datetime information. The fourth section, clock_seq_hi_and_reserved, is somewhat of a misnomer. Although “clock sequence” may sound like another value taken from another internal process, it is in fact just a randomly generated 16-bit value that helps decrease the likelihood that two v1 UUIDs could ever be identical. FInally, the last 12 characters are taken from the device MAC address.
Concatenating the datetime with the device MAC address into a single label produces a combination of letters and numbers that is virtually impossible to replicate. For two separate UUID v1 or UUID v2s to be identical, they would have to be produced by the same device at precisely the same time. Adding in the additional randomly generated string makes the probability of duplication, or “collision,” infinitesimally small.
In most use cases, the identifiable time and device information within the UUID is not a drawback. In fact, within a distributed system, this can be an advantage––it eliminates the need to designate a single authority to generate identifiers, and allows you to see which nodes within the network generated UUIDs. In situations where it is important for the objects you’re identifying to not be tied to the physical hardware on which their ID was created, however, it is likely best to opt for versions 3, 4 or 5.
Version 2
The only difference in version 2 is that part of datetime information that would be in a v1 UUID is replaced by a local domain number. While this can be useful in certain situations, it limits the uniqueness of the UUID and raises certain privacy concerns. For this reason, v2 UUIDs are not widely used.
Versions 3 and 5
Like versions 1 and 2, versions 3 and 5 UUIDs are also non-random in the sense that they use inputted information to generate a 32-character alphanumeric value. However, these versions are created based on “namespace” and “name” data rather than time- and node-related values. The namespace input is itself a UUID that denotes the application environment where the value will be used. The name value often conveys what the ID will be used for, i.e. a user or account name, and is often supplied directly (or dynamically) by the developer generating the IDs within an application.
Namespace and name inputs are then run through a hashing algorithm to generate the UUID. The main difference between v3 and v5 UUIDs is the hashing algorithm used to generate them––v3 uses MD5, and v5 uses SHA-1. When using a package or library to generate UUIDs within an application, namespace and name values are often passed as arguments to a method that outputs UUIDs of these two versions. These packages also commonly provide ways of dynamically accessing frequently used namespage values like DNS and URL. For example, creating a v3 UUID with the Python UUID library would look like this:
import uuid
UUID3 = uuid.uuid3(uuid.NAMESPACE_URL, "item/143462")
print("Here is a version 3 UUID! ", UUID3)
# Output: Here is a version 3 UUID! fbf825a3-79e0-3877-b486-cb53da71d414Version 4
Version 4 UUIDs are probably the simplest to understand, and perhaps the most frequently used as well. These UUIDs are simply randomly generated values (derived from a cryptographically secure generator) that do not contain any namespace, device, or time-based information.
They look like this: adbbf6bd-1746-4545-a3ce-8b153a7a31b2
The only non-random character in this value is the “4” in the first position of the third section (after the second hyphen), denoting that this is a v4 UUID. Other than that, every other character is just a random number from 0-9, or lowercase letter from a-z.
Here is a recap of the attributes, possible advantages, and potential pitfalls of each UUID version:


A comparison of the five different UUID versions.
How do you generate UUIDs in applications?
While you may be tempted to “roll your own” UUID function and use it in an application, this is not the best practice. The Internet Engineering Task Force––the organization that publishes the standards arounds UUIDs––has laid out certain guidelines for the level of uniqueness UUIDs need to maintain. And while it is possible to write a simple function in your language of choice that returns compliant UUIDs (the criteria for which are outlined here, in case you’re curious), you probably won’t want to maintain that code to ensure that its output keeps making the grade.
Luckily, there are several well-maintained libraries you can use that will take care of this task for you. In JavaScript, for example, you can use the uuid npm package. After running `npm install uuid`, you can specify which UUID version you’d like to use in the import statement:
`import { v1 as uuidv1 } from 'uuid';`
Creating a Version 1 UUID would then be as simple as calling `uuidv1()` as a function, or by passing in additional `options` specifying node and time data:
const v1options = {
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678,
};
uuidv1(v1options);In a Python environment, the UUID library demonstrated above is a standby tool, though many developers have created other options to serve specific use cases. Unless your application or database calls for a nuanced usage of UUIDs that a popular package cannot service, the best practice is to use a well-maintained and regularly updated library to ensure that the underlying cryptographic technologies creating your identifiers remain state-of-the-art.
Use cases for UUIDs
UUIDs are appropriate for a wide variety of use cases across different types of systems, since their universal nature means they can be generated anywhere within a network. This eliminates the need to designate this task to a single system node. Here are some common examples of how UUIDs are used in the wild:
Web applications
Within a web application, UUIDs can be generated within the front end of the app without necessitating a call to a server or database. This makes UUIDs ideal for labeling data objects related to state management, such as user or session IDs.
Analytics systems
Any third-party application system that integrates into a web or mobile application such as marketing, analytics, and advertising tools will likely have a need to generate unique identifiers. For example, an advertising company that wants to identify the impressions, clicks, and other events within a single user session could generate a UUID at the beginning of a session, then associate individual events with this single ID.
Database systems
In distributed database systems, UUIDs can be very useful for splitting up large tables and storing them across multiple servers. Each portion of the same table can be given the same UUID, thereby making the data identifiable as a single set when performing read/write operations.
Interested in the topic of user identity and maintaining cross-system data identification? Check out how Customer Data Platforms help engineering teams simplify cross-channel data collection, streamline data transformation and delivery, and address other technical challenges of the modern data ecosystem.
Note: If you ever have a need to determine the likelihood of a UUID collision, or probability theory is just something that brings joy to your heart, you can use the Birthday Problem.







